Uploading
In general, HiCognition allows two different types of uploads:
- either directly from your computer (this is explained in the regions and features section in more detail)
- or by providing it via an online location.
We highly recommend direct ingestion via online locations with big files; not only do you not need to wait (HiCognition will inform you once the download is finished), but it also avoids time-out errors with very big files.
Online repositories
HiCognition can deal with multiple repositories and their unique API interfaces. Hicognition was developed to be extendable with more repositories and special login schemes they provide. We currently support 4D Nucleome and ENCODE. In the case of 4D Nucleome, you can directly use the unique ID for a data item, and Hicogntion will be able to fetch it for you directly.
Generic online sources
Other locations or web sources can be used to ingest the data directly to HiCognition. These include any web source that provides a link that can be triggered via the browser. We currently use this feature to download from Dropbox, Amazon cloud storage buckets or data sources directly linked in papers or homepages.
4D Nucleome Example
Choose the 4D Nucleome uploading option from the menue.
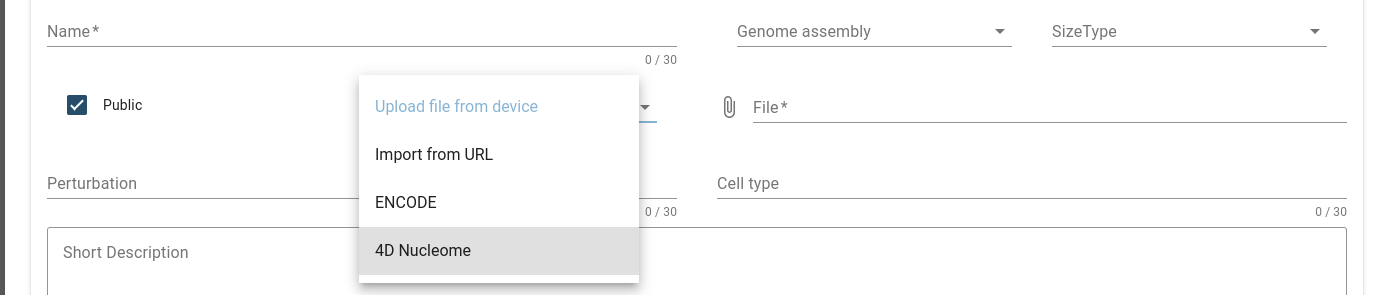
Now you will get the following form that has two new features:
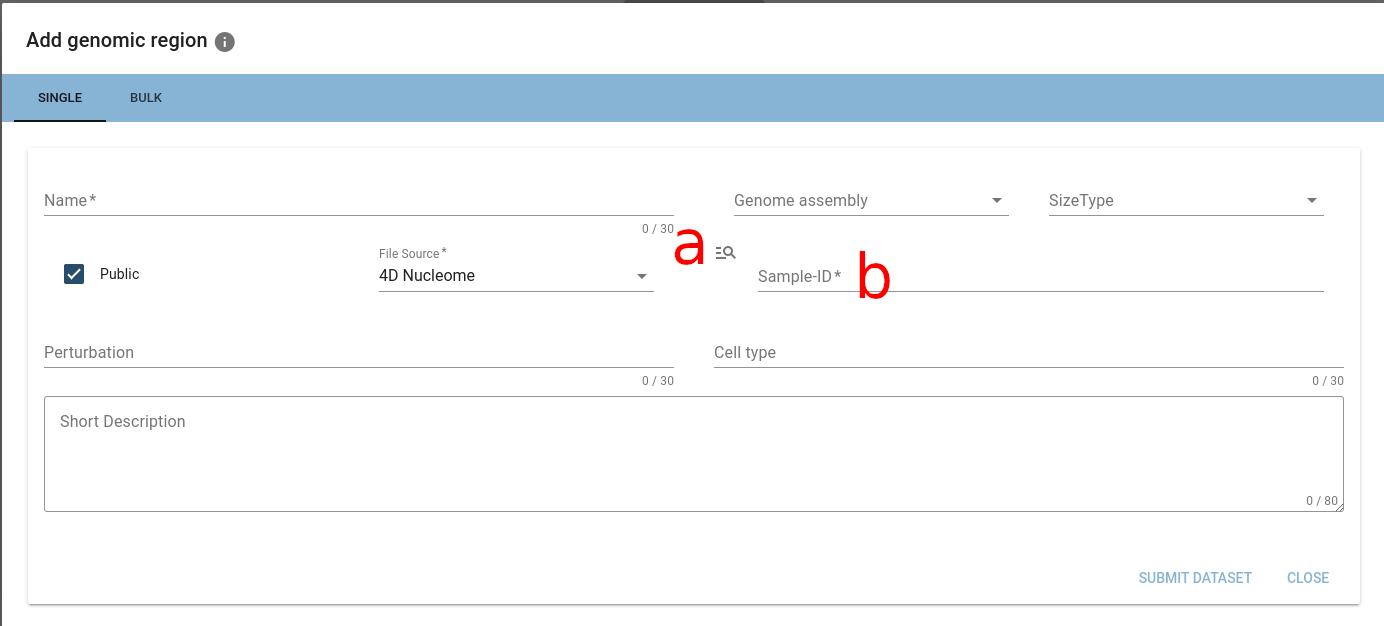
- a: a quick link to the repositories data browser (it will be opened in a new tab)
- b: a text field that requires a unique datasource ID
In the Data Browser
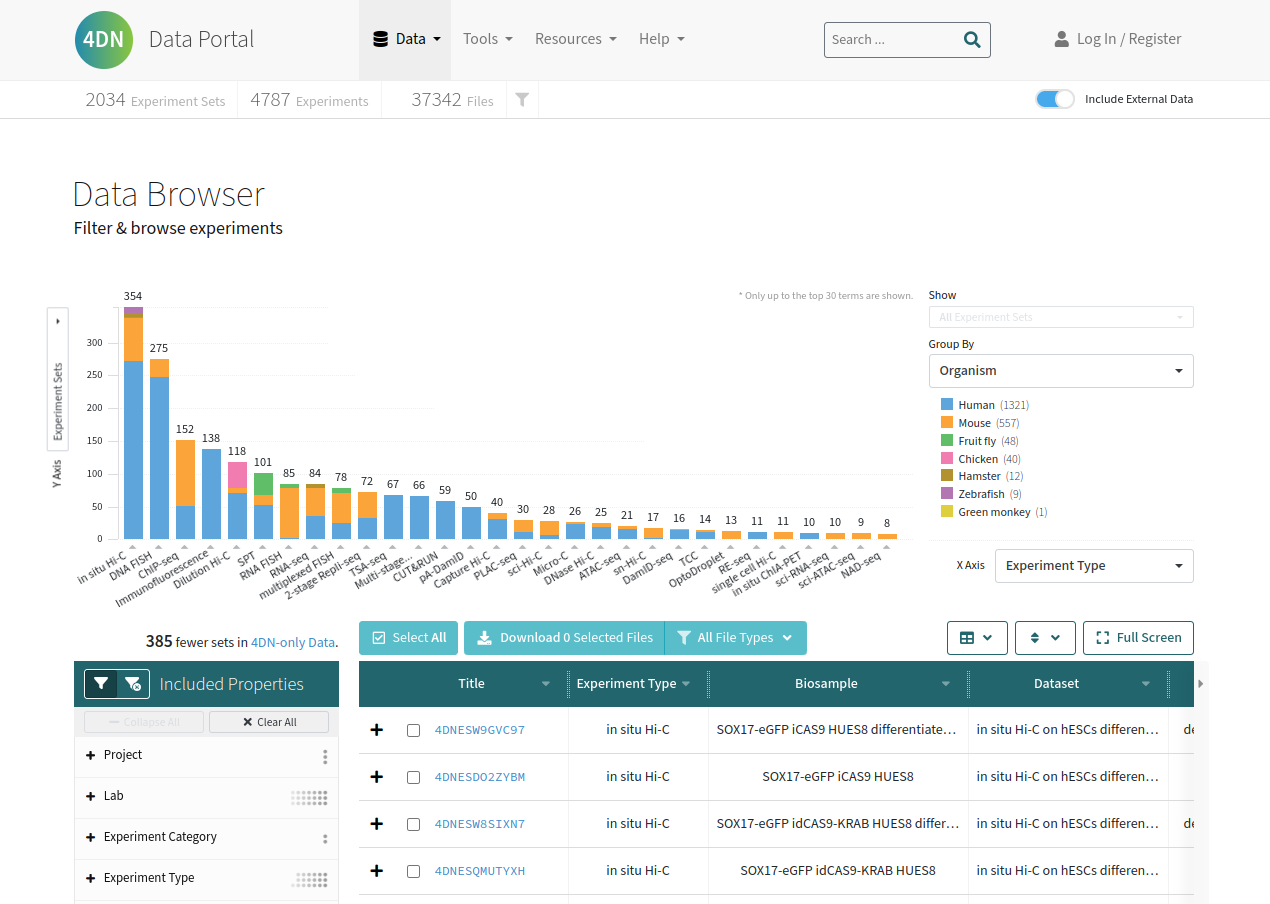
we found following bed file and now need to copy the unique identifier, 4D Nucleome has a button (a) to copy the ID to your clipboard.
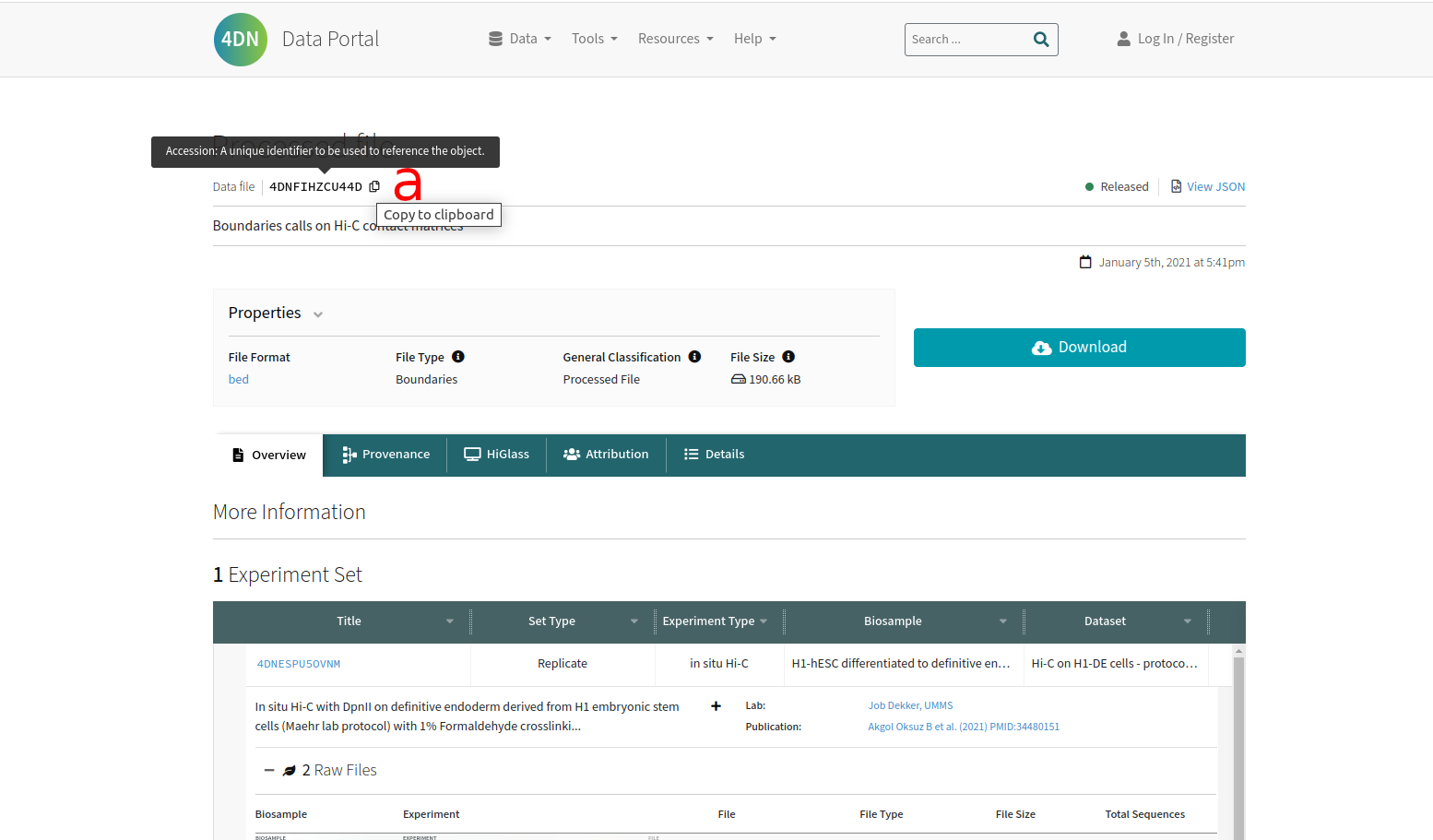
After entering the ID HiCognition will use the 4D Nucleome API to pull metadata and help you fill out the form (experimental), you can always manually change this information.
ENCODE and “import from URL”
Some repositories do not have a unique ID, since they allow multiple files under one identifier.
In this case HiCognition will use the direct file link as an identifier, currently the user needs to manually select which filetype he wants to upload as well.
